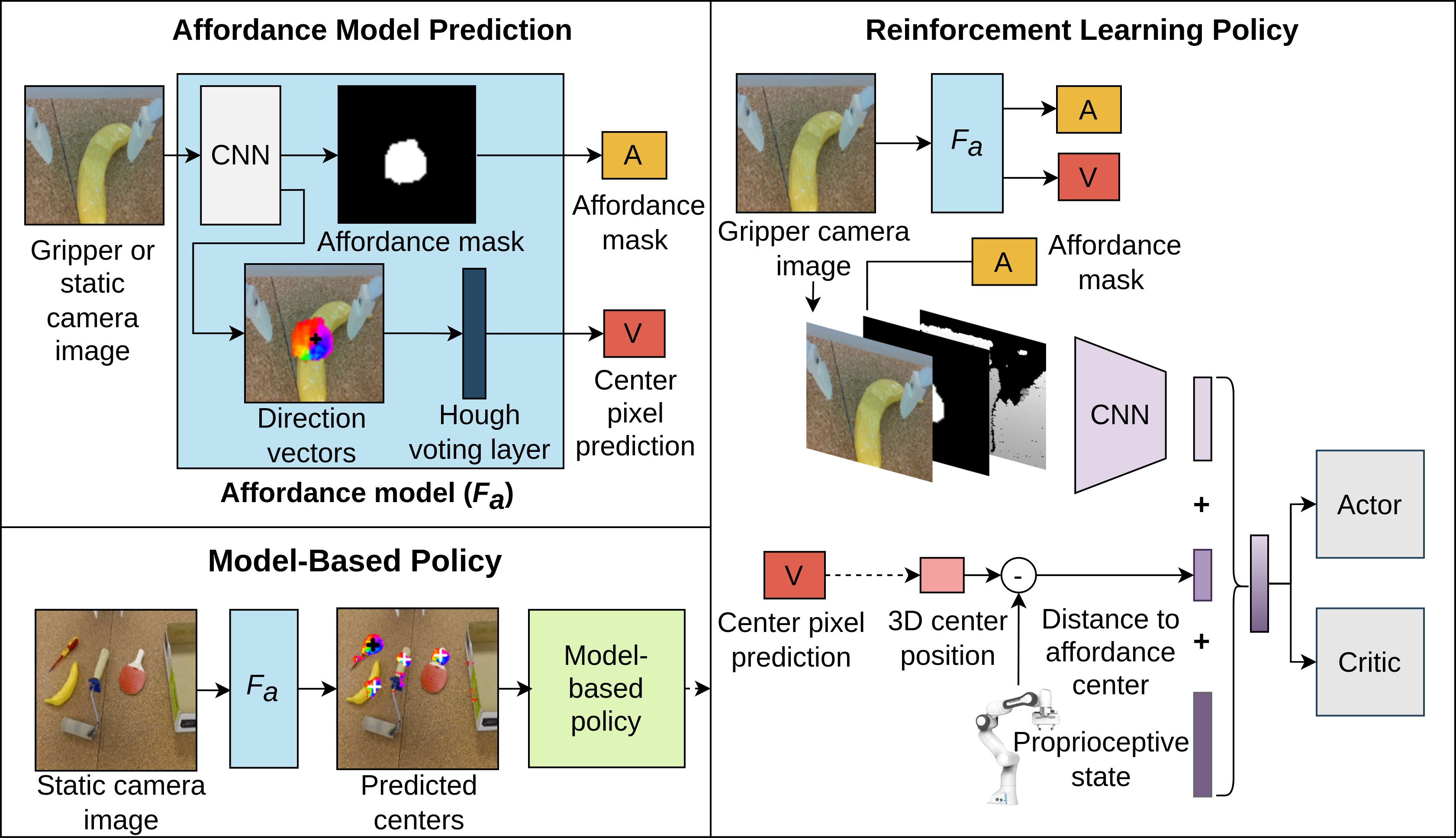
Robots operating in human-centered environments should have the ability to understand how objects function: what can be done with each object, where this interaction may occur, and how the object is used to achieve a goal. To this end, we propose a novel approach that extracts a self-supervised visual affordance model from human teleoperated play data and leverages it to enable efficient policy learning and motion planning. We combine model-based planning with model-free deep reinforcement learning (RL) to learn grasping policies that favor the same object regions favored by people, while requiring minimal robot interactions with the environment. We find that our policies train 4x faster than the baselines and generalize better to novel objects because our visual affordance model can anticipate their affordance regions.
We evaluate our algorithm, Visual Affordance-guided Policy Optimization (VAPO), with both diverse simulation manipulation tasks and real world robot tidy-up experiments to demonstrate the effectiveness of our affordance-guided policies.